Information Creeping Vs Data Scratching Therefore, research study the procedures thoroughly before you decide on the one that best suits your needs. Data crawling digs deep right into the World Wide Web to obtain the information. Think about spiders or robots, scavenging with the Web to determine what is essential to your search. Spiders are working on a formula that provides appropriate guidelines. Data scratching is defined as collecting information and then scraping it. Internet spiders have actually been evolving for several years and they possess specific high qualities which make them more desirable. Web spider architecture makes up managerial spiders which are responsible for handling worker spiders that service the very same link. We can opt for either technique relying on the nature of details we are seeking out. Information scratching and data creeping can be based on a variety of obstacles, such as lawful and moral problems, technological difficulties, and quality concerns. It is necessary to respect the information proprietor's rights and approvals, and avoid any type of violations of the legislation. Some pages or files may have vibrant, intricate, or encrypted material that can make information scuffing or creeping difficult or impossible. To get over these obstacles, you might need to utilize advanced methods, such as browser automation, proxies, or APIs. Furthermore, some pages or documents might have unreliable, incomplete, or obsolete information that can influence the reliability and legitimacy of your outcomes.
Significant Distinction Between Web Scratching And Web Crawling
The Portable Paper Style layout is extremely essential for companies that call for a significant degree of information security. Considering that both scuffing and creeping are rather relevant procedures, it's no wonder that people obtain confused concerning it. Pricing and rival evaluation-- companies are increasingly relying upon data scrapes to come up with a rates method. Scrapers can aid locate, gather, and extract the prices information of competitors and track their on-line habits, discounts, and pricing Article source techniques. Information scratching objectives to download and install info, whereas data crawling refers to the indexing of web pages. In this instance, the typical scratched information collections are prices, summaries, testimonials, offers, and so on.Artists Are Suing Artificial Intelligence Companies and the Lawsuit Could Upend Legal Precedents Around Art - ARTnews
Artists Are Suing Artificial Intelligence Companies and the Lawsuit Could Upend Legal Precedents Around Art.
Posted: Fri, 05 May 2023 07:00:00 GMT [source]

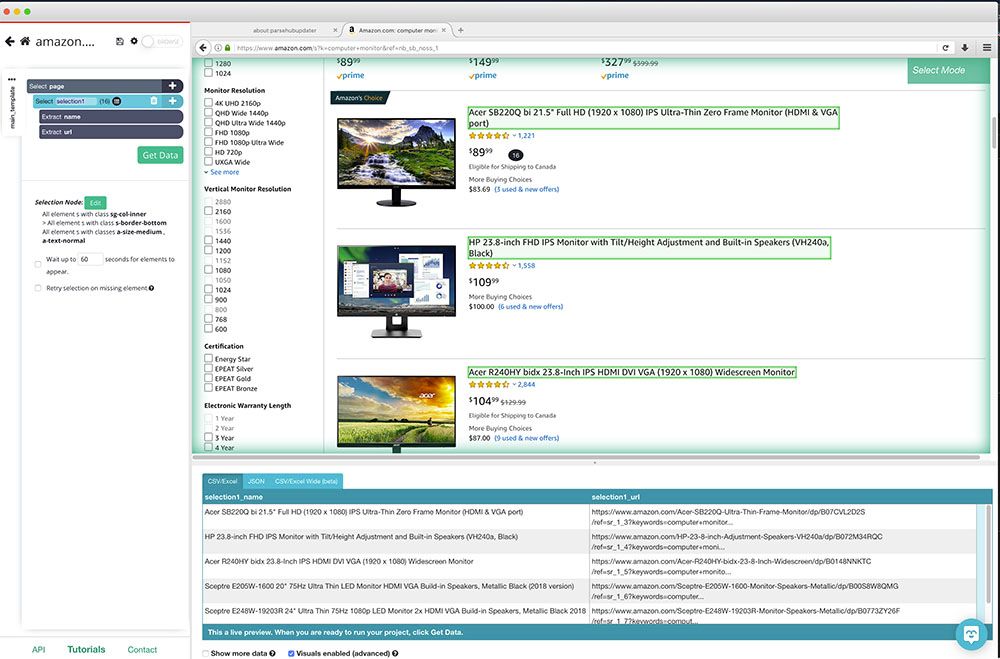
Scratching Vs Creeping
Data creeping services take out duplicate details from the text that could have been copied/pasted, as they can not tell the distinction. In the future, advanced spiders will certainly have the ability to tell the difference. Information scuffing is an excellent approach when you wish to draw out some information that is tough to get to, such as asset prices, as an example. Often, the information ends https://postheaven.net/ormodalcmi/why-vehicle-market-must-take-advantage-of-information-scuffing-in-2020 up being copied, as this process isn't created to omit the exact same data from different sources.- Data crawling is done on a grand scale that calls for special treatment as not to upset the sources or damage any legislations.Which gives is meant to supply a big storage space of scraped information for veteran use, allowing you to browse the exact response to your concerns in the most optimum time-frames.JPEG is a basic style for every single electronic picture, which is why it's the very best layout to pick for scuffing photos.Consider spiders or crawlers, scavenging through the Net to find out what is essential to your search.